
Projects
 | Contrast Motif Detection
A contrast sequential pattern is a pattern that occurs frequently in one sequence group but not in the others. We introduce method for analyzing event sequences by detecting contrasting motifs; the aim is to discover subsequences that are significantly more similar to one set of sequences vs. other sets.
|
 | Selfie Drone Stick
A quadcopter can capture photos from vantage points unattainable for a human photographer, but teloperating it to a good viewpoint is a non-trivial task. Since humans are good at composing photos, the aim of our research is to leverage deep learning to create a customizable flight controller that can capture photos under the guidance of a human photographer. Our system, the Selfie Drone Stick, allows the user to assign a vantage point to the quadcopter based on the phone's sensors. The user takes a selfie with the phone once, and the quadcopter autonomously flies to the target viewpoint. The proliferation of open source deep learning models provided us with a large variety of options for the computer vision and flight control systems. This article describes three key innovations required to deploy the models on a real robot: 1) a new architecture for rapid object detection, DUNet; 2) an abstract state representation for transferring learning from simulation to the hardware platform; 3) reward shaping and staging paradigms for training a deep reinforcement learning controller. Without these improvements, we were unable to learn a flight controller that adequately supported the intuitive user interface.
|
 | Learning from Demonstration in VR
One of the advantages of teaching robots by demonstration is that it can be more intuitive for users to demonstrate rather than describe the desired robot behavior. However, when the human demonstrates the task through an interface, the training data may inadvertently acquire artifacts unique to the interface, not the desired execution of the task. Being able to use one’s own body usually leads to more natural demonstrations, but those examples can be more difficult to translate to robot control policies. We quantify the benefits of using a virtual reality system that allows human demonstrators to use their own body to perform complex manipulation tasks. We show that our system generates superior demonstrations for a deep neural network without introducing a correspondence problem. The effectiveness of this approach is validated by comparing the learned policy to that of a policy learned from data collected via a conventional gaming system, where the user views the environment on a monitor screen, using a Sony Play Station 3 (PS3) DualShock 3 wireless controller as input.
|
 | Signed Multiplex Link Prediction
Networks extracted from social media platforms frequently include multiple types of links that dynamically change over time; these links can be used to represent dyadic interactions such as economic transactions, communications, and shared activities. Organizing this data into a dynamic multiplex network, where each layer is composed of a single edge type linking the same underlying vertices, can reveal interesting cross-layer interaction patterns. We created a comprehensive framework, SMLP (Signed Multiplex Link Prediction), in which link existence likelihoods for the target layer are learned from the other network layers. These likelihoods are used to reweight the output of a single layer link prediction method that uses rank aggregation to combine a set of topological metrics and mutual information to predict the valence of interaction.
|
 |
Autonomous Quadcopter Videographer
Quadcopters are well-suited to act as videographers and are capable of shooting from locations that are unreachable for a human. Our project evaluated the performance of two vantage point selection strategies: 1) a reactive controller that tracks the subject's head pose and 2) combining the reactive system with a POMDP planner that considers the target's movement intentions.
|
 |
Normative Agent Architectures for Modeling Human Health Habits
Norms are an important part of human social systems, governing many aspects of group decision-making. Normative agent architectures extend on standard multi-agent systems by incorporating computational machinery for reasoning about social norms. Within the multi-agent research community, the study of norm emergence, compliance, and adoption has resulted in new architectures and standards for normative agents; however few of these models have been successfully applied to real-world public policy problems. We have developed two agent architectures, LNA (Lightweight Normative Architecture) and CSL (Cognitive Social Learners) for predicting trends in smoking cessation resulting from the UCF smoke-free campus initiative.
|
 |
KPark: Crowdsourcing Parking Lot Occupancy using a Mobile Phone Application
KPark is a mobile phone app for crowdsourcing parking availability on the UCF campus. This is an example of participatory sensing---a specialized form of crowdsourcing for mobile devices in which the users act as sensors to report on local environmental conditions, such as traffic, pollution, and wireless signal strength. In additional to crowdsourced data, KPark uses an agent-based simulation of transportation patterns on the UCF campus to improve the accuracy of predictions in cases where few users have submitted reports.
|
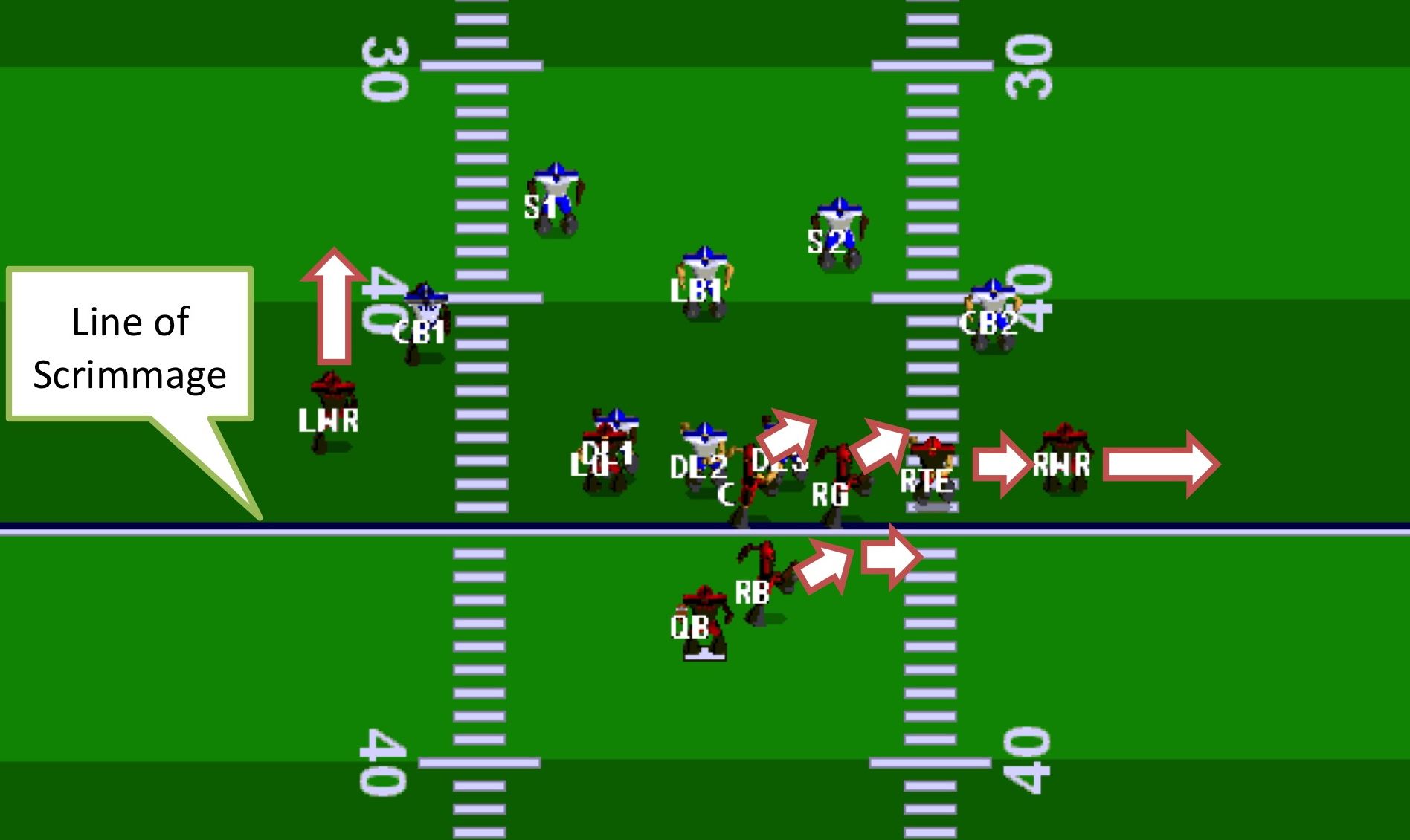 |
Learning Individual and Team Behaviors in Adversarial Games
This project focuses on the use of machine learning techniques to learn policies by demonstration and also to predict future player actions from log data. To explore the problem of decision-making in multi-agent adversarial scenarios, we use our approach for both offline play generation and real-time team response in the Rush 2008 American football simulator.
|
 |
Agents in Virtual Worlds
We aim to study group dynamics in these virtual worlds by collecting and analyzing public conversational patterns of users grouped in close physical proximity. To do this, we created a set of tools for monitoring, partitioning, and analyzing unstructured conversations between changing groups of participants in Second Life, a massively multi-player online user-constructed environment. For this project, we also built a social recommender system that assists user navigation in the virtual world.
|
 |
Inquiry Modeling for ITSs
This project focused on the development of intelligent tutoring systems (ITS) with two emerging methodologies: (1) a partially observable Markov decision process (POMDP) for representing the learner model and (2) inquiry modeling, which informs the learner model with questions learners ask during instruction. Tractability issues have previously precluded the use of probabilistic planners in ITS models, which we overcame by creating a set of new ITS-specific representations, state queues and observation chains. In collaboration with Dr. Sae Schatz at IST, we were able to do a large human subjects study showing the benefits of our approach for the ONR Next-generation Expeditionary Warfare Intelligent Training system. Users of our ITS achieved post-training scores averaging up to 4.5 times higher than users who practiced without support.
|
 |
User Interfaces for Multi-Robot Systems
Multi-robot tasks can be complicated due to the need for tight temporal coupling between robots. To ameliorate this problem, we developed a paradigm for allowing subjects to configure a user interface for multi-robot manipulation tasks; using a macro acquisition system for learning combined manipulation/driving tasks.
|
 |
Active Learning for Crowdsourced Data
Crowdsourcing has become an popular approach for annotating the large quantities of data required to train machine learning algorithms; however one drawback is that labelers often make errors even on simple labeling tasks. Active learning provides a mechanism to reduce labeling costs by affordably selecting an appropriate subset of instances to label, but can be very vulnerable to noisy data. We are researching active learning methods that are designed to be robust to labeler errors.
|
 |
Learning Game Bots using Inverse Reinforcement Learning
In this project, we examine the problem of teaching a bot to play like a human in first-person shooter game combat scenarios. Our bot learns attack, exploration and targeting policies from data collected from expert human player demonstrations in Unreal Tournament. One key difference between human players and autonomous bots lies in the relative valuation of game states. To capture the internal model used by expert human players to evaluate the benefits of different actions, we use inverse reinforcement learning to learn rewards for different game states.
|
 |
Unit Micromanagement Tactics in Starcraft
Constructing an effective real-time strategy bot requires multiple interlocking elements including a well-designed architecture, efficient build order, and good strategic/tactical decision-making. However even when the bot’s high-level strategy and resource allocation is sound, poor battlefield tactics can result in unnecessary losses. This project focuses on the problem of avoiding troop loss by identifying good tactical groupings. Banding separated units together using UCT (Upper Confidence bounds applied to Trees) along with a learned reward model outperforms grouping heuristics at winning battles while preserving resources. Our Adjutant bot design won the best Newcomer honor at CIG 2012.
|
 |
Multi-Label Relational Neighbor Classifier using Social Context Features
Networked data, extracted from social media, web pages, and bibliographic databases, can contain entities of multiple classes, interconnected through different types of links. This project focuses on the problem of performing multi-label classification on networked data, where the instances in the network can be assigned multiple labels. We developed a multi-label iterative relational neighbor classifier that employs social context features (SCRN). Our classifier incorporates a class propagation probability distribution obtained from instances’ social features, which are in turn extracted from the network topology. This class-propagation probability captures the node’s intrinsic likelihood of belonging to each class, and serves as a prior weight for each class when aggregating the neighbors’ class labels in the collective inference procedure. Experiments on several real-world datasets demonstrate that our proposed classifier boosts classification performance over common benchmarks on networked multi-label data.
|
 |
Hierarchical Influence Maximization for Advertising in Multi-agent Markets
Maximizing product adoption within a customer social network under a constrained advertising budget is an important special case of the general influence maximization problem. Specialized optimization techniques that account for product correlations and community effects can outperform network-based techniques that do not model interactions that arise from marketing multiple products to the same consumer base. However, it can be infeasible to use exact optimization methods that utilize expensive matrix operations on larger networks without parallel computation techniques. We developed a hierarchical influence maximization approach for product marketing that constructs an abstraction hierarchy for scaling optimization techniques to larger networks. An exact solution is computed on smaller partitions of the network, and a candidate set of influential nodes is propagated upward to an abstract representation of the original network that maintains distance information. This process of abstraction, solution, and propagation is repeated until the resulting abstract network is small enough to be solved exactly.
|
 Contact:
Contact: